Every organization talks about psychological safety and open collaboration. Almost none can tell you whether those values actually show up in Monday’s meeting.
That gap is the problem my team and I set out to solve.
Research consistently shows that team failures trace back to interpersonal dynamics, not technical skill gaps. Google’s Project Aristotle found psychological safety, not talent predicts team performance. Yet the micro-moments that create or erode safety (a dismissive response, an ignored idea, an imbalance in who speaks) are nearly impossible to observe and measure at scale. Traditional methods require ten hours of expert human coding for every hour of team interaction. That makes large-scale research prohibitively expensive and leaves practitioners flying blind.
We recognized this as both a scientific bottleneck and a design opportunity.
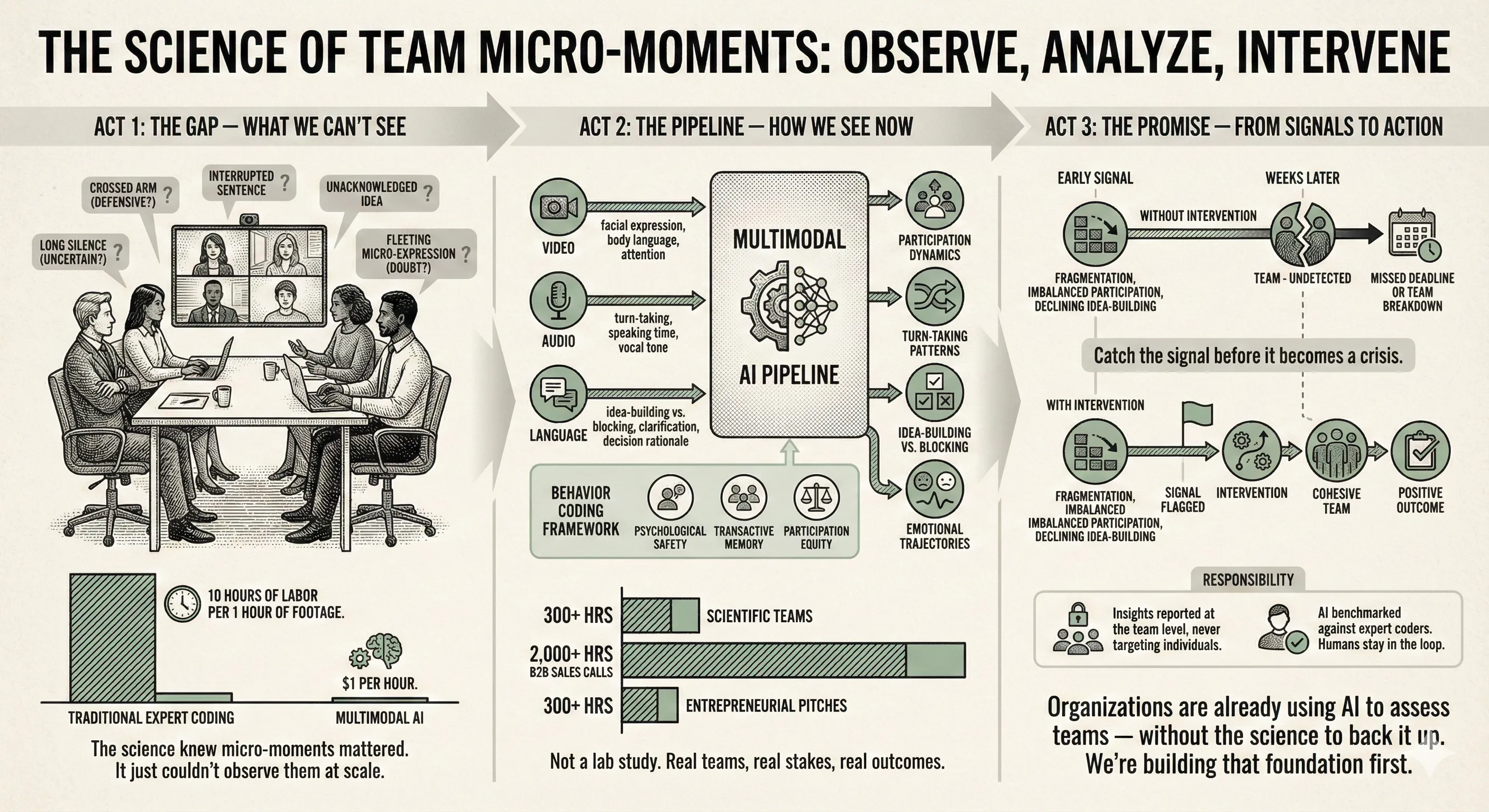
The approach: We built a multimodal AI pipeline that uses multimodal AI to simultaneously analyze video, audio, and language from real team interactions — at roughly $1 per hour of footage, compared to hundreds of dollars in expert labor. The system extracts behavioral signals like participation dynamics, turn-taking patterns, idea-building versus blocking behaviors, and emotional trajectories across a conversation.
The dataset is deliberately ambitious: 300+ hours of scientific research teams, 2,000+ hours of B2B sales calls, and 300+ hours of entrepreneurial pitch negotiations. This breadth lets us ask not just “what works?” but “what generalizes?”, separating universal collaboration principles from context-specific patterns.
The technical pipeline is grounded in organizational theory. We synthesized decades of team science research to create a behavior coding framework and designed prompts around these validated constructs: transactive memory, shared mental models, Tuckman’s team development stages etc. so the AI extracts features that map onto decades of team science, not just surface-level sentiment.
Rigor and responsibility by design: We designed thorough and comprehensive evalutaion pipeline to assess and improve AI annotations. They are benchmarked against expert human coders with systematic audits. Privacy protection is built into the pipeline from the start: data is processed under strict access controls and behavioral insights are reported at the team level rather than targeting individuals.
What it reveals: Early results show that specific behavioral patterns (like how often teams ask clarifying questions, or how quickly they recover after disagreement) predict outcomes weeks later with meaningful accuracy. The goal is an early-warning system: flag a team showing fragmentation signals before a missed deadline, not after.
Why it matters beyond academia: Organizations are already deploying AI to assess teams, but without empirical grounding or ethical guardrails. I’m building the research infrastructure that should have come first: validated methods, open-source tools, and a framework that keeps human judgment central while making behavioral intelligence scalable.
This project sits at the intersection of organizational science, AI systems design, and responsible technology, which is exactly where I want to work. The technical challenge is building reliable AI measurement. The harder, more interesting challenge is building it in a way that surfaces human collaboration without reducing people to data points.
Collaborators: Dr. Matt Groh; Dr. Brian Uzzi; Max Chalekson
-
This project has won the finalist (top 10% of 250+ proposals from scholars across the world) for the AI for Organizations Grand Challenge organized by Google DeepMind and Stanford HAI in 2025.
-
[IN REVIEW]: A Point of View article for the Journal of Organizational Design 2026